
RHOS
About
Hi, this is the website of the RHOS lab. We study Embodied AI, Physical Reasoning, and Human Activity Understanding. We are building a knowledge and reasoning-driven system that enables intelligent agents/robots to perceive human activities, reason human behavior logics, learn skills from human activities and interact with the environment.
Research Interests:
(S) Embodied AI: how to make agents learn skills from humans and interact with humans & scenes & objects.
(S-1) Human Activity Understanding: how to learn and ground complex/ambiguous human activity concepts (body motion, human-object/human/scene interaction) and object concepts from multi-modal information (2D-3D-4D).
(S-2) Visual Reasoning: how to mine, capture, and embed the logic and causal relations from human activities.
(S-3) General Multi-Modal Foundation Models: especially for human-centric perception tasks.
(S-4) Activity Understanding from A Cognitive Perspective: work with multidisciplinary researchers to study how the brain perceives activities.
(E) Human-Robot Interaction for hospital, home, factory, etc.: work with experts in different domains to develop intelligent robots to help people.
Contact
Email: yonglu_li[at]sjtu[dot]edu[dot]cn Shanghai Jiao Tong University Shanghai Innovation Institute
Recruitment
We are actively looking for self-motivated students (Master/PhD, 2026 spring & fall), interns/engineers/visitors (CV/ML/ROB/NLP/Math/Phys background, always welcome) to join us in Machine Vision and Intelligence Group (MVIG). If you have the same/similar interests, feel free to email me your resume.
News and Olds
Projects
HAKE
Human Activity Knowledge Engine (HAKE) is a knowledge-driven system that enables intelligent agents to perceive human activities, reason human behavior logics, learn skills from human activities, and interact with objects and environments.
OCL
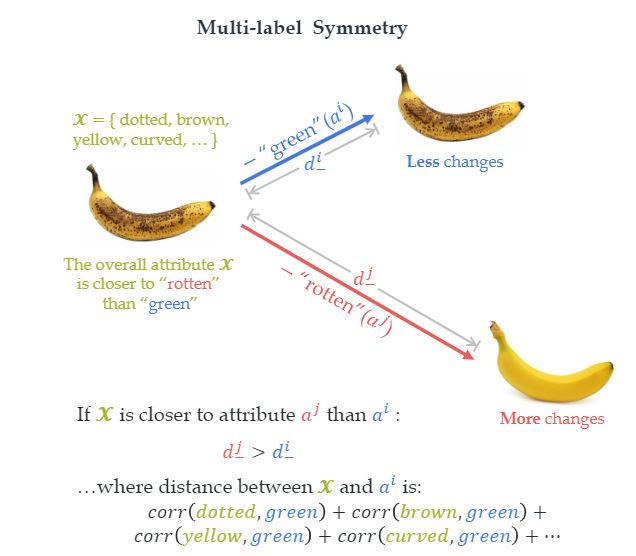
We propose a challenging Object Concept Learning (OCL) task to push the envelope of object understanding. It requires machines to reason out object affordances and simultaneously give the reason: what attributes make an object possess these affordances.
Pangea
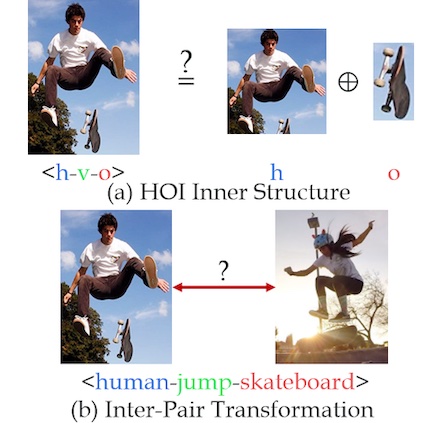
We design an action semantic space given a verb taxonomy hierarchy that covers a vast range of actions. Thus, we can gather multi-modal datasets into a unified database in a unified label system, i.e., bridging “isolated islands” into a “Pangea”. Therefore, we propose a bidirectional mapping model between physical and semantic spaces to utilize Pangea fully.
EgoPCA
We rethink and propose a new framework as an infrastructure to advance Ego-HOI recognition by Probing, Curation, and Adaptation (EgoPCA). We contribute comprehensive pre-train sets, balanced test sets, and a new baseline, which are complete with a training-finetuning strategy and several new and effective mechanisms and settings to advance further research.
Human-Robot Joint Learning
[ICRA 2025 Best Paper Award on Human-Robot Interaction] A human-robot joint learning teleoperation system for faster data collection, less human effort, and efficient robot manipulation skill acquisition.
Video-Distillation
We provide the first systematic study of video distillation and introduce a taxonomy to categorize temporal compression. This taxonomy motivates our unified framework for disentangling the dynamic and static information in videos. It first distills the videos into still images as static memory and then compensates the dynamic and motion information with a learnable dynamic memory block.
Check out some of our work
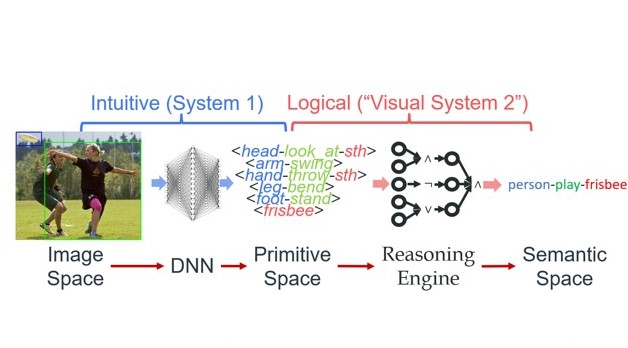

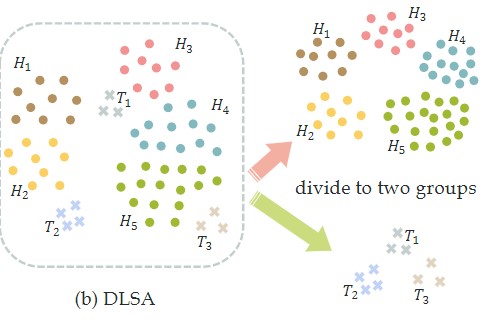
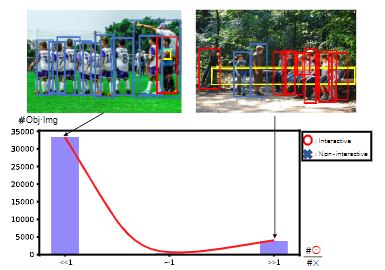
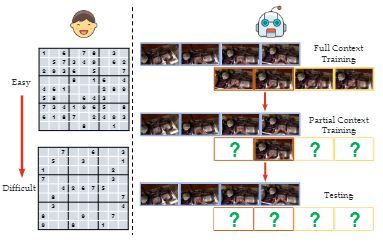
Publications
*=equal contribution
#=corresponding author
---Robot Demos---
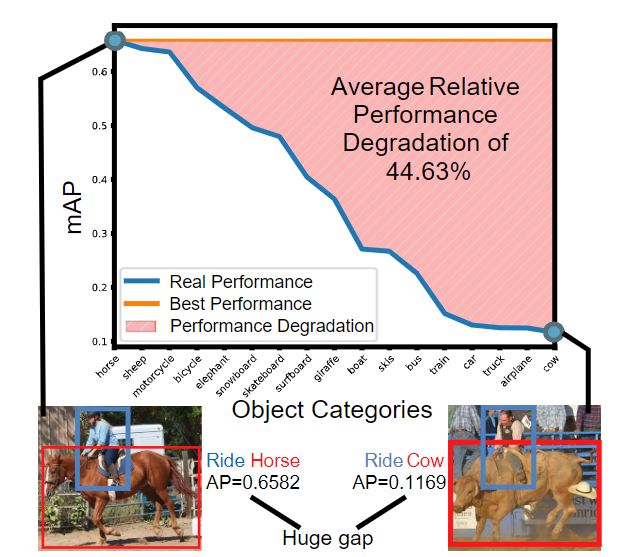
Beyond Object Recognition: A New Benchmark towards Object Concept Learning
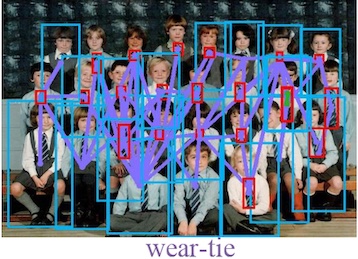
Discovering A Variety of Objects in Spatio-Temporal Human-Object Interactions
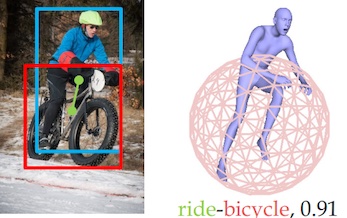
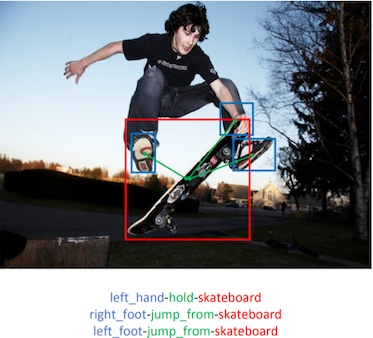
HAKE: Human Activity Knowledge Engine
| Main Repo: | HAKE Star | ||
| Sub-repos: | Torch Star | TF Star | HAKE-AVA Star |
| Halpe Star | HOI List Star |
Human Trajectory Prediction with Momentary Observation
HOI Analysis: Integrating and Decomposing Human-Object Interaction
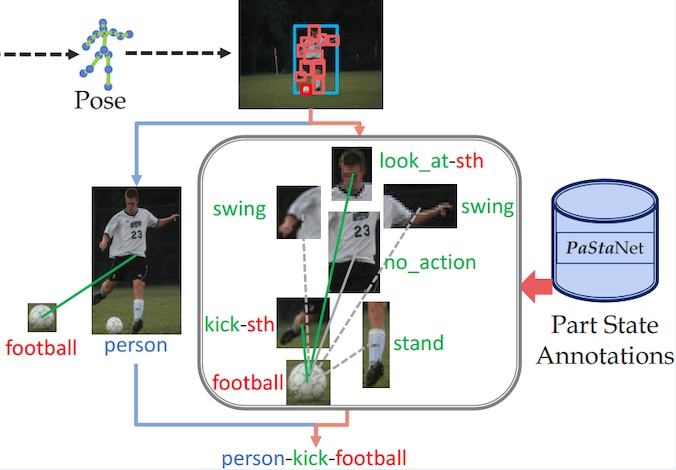
PaStaNet: Toward Human Activity Knowledge Engine
Oral Talk: Compositionality in Computer Vision in CVPR 2020
SRDA: Generating Instance Segmentation Annotation via Scanning, Reasoning and Domain Adaptation
Beyond Holistic Object Recognition: Enriching Image Understanding with Part States
Optimization of Radial Distortion Self-Calibration for Structure from Motion from Uncalibrated UAV Images
People
































Alumni:
