The Labyrinth of Links: Navigating the Associative Maze of Multi-modal LLMs
MVIG-RHOS, SJTU

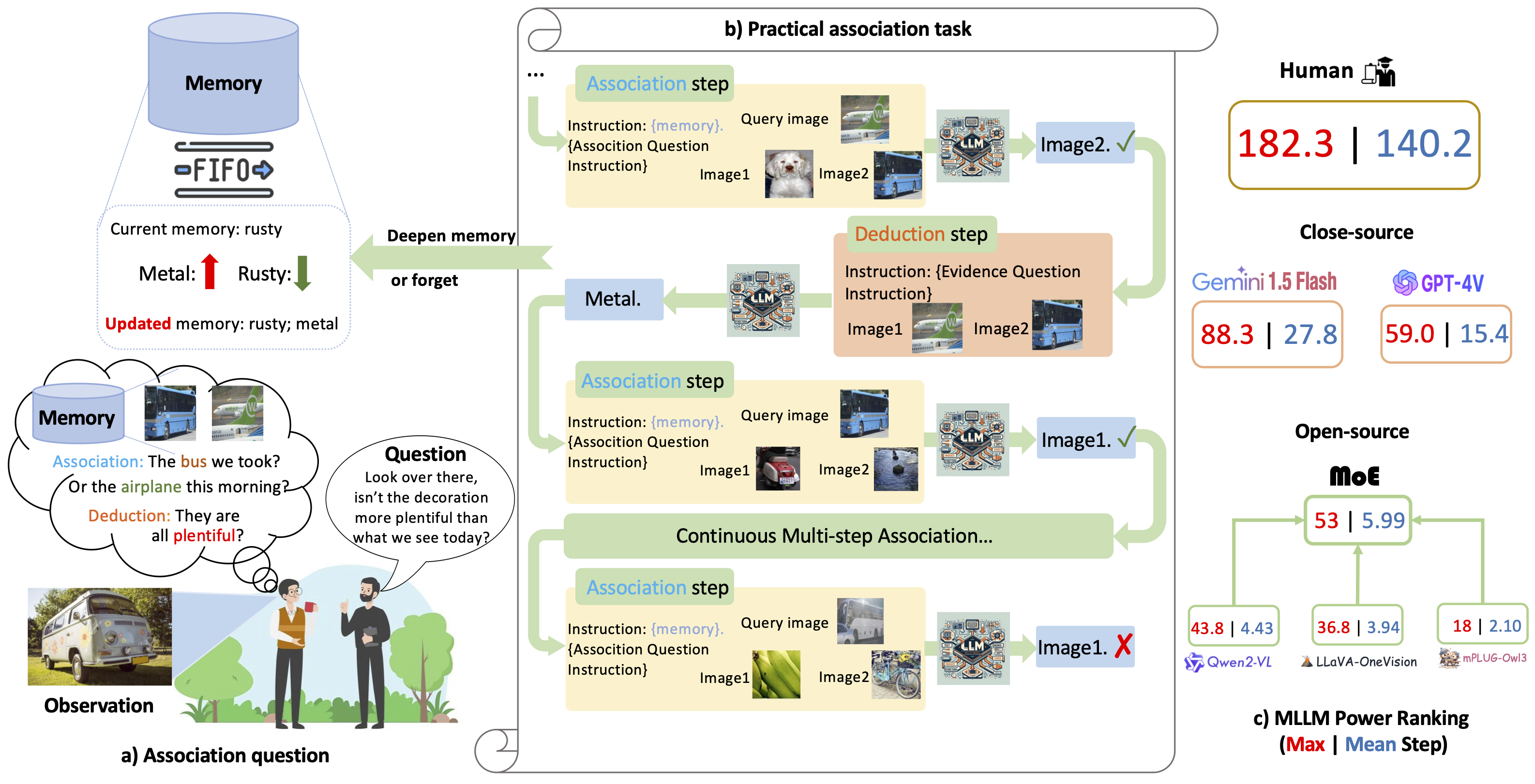
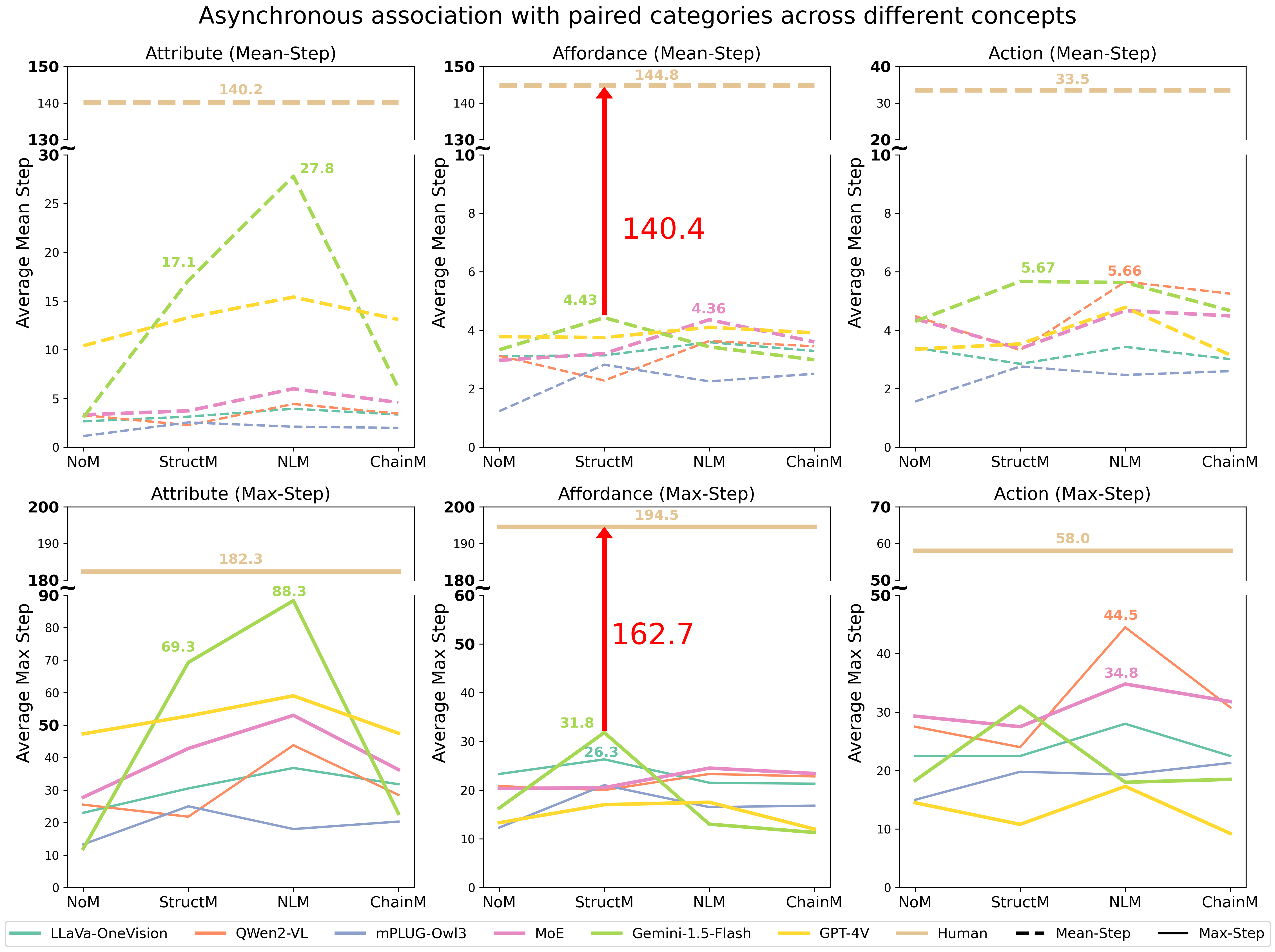
Multi-modal Large Language Models (MLLMs) have exhibited impressive capability. However, recently many deficiencies of MLLMs have been found compared to human intelligence, e.g., hallucination. To drive the MLLMs study, the community dedicated efforts to building larger benchmarks with complex tasks. In this paper, we propose benchmarking an essential but usually overlooked intelligence: association, a human's basic capability to link observation and prior practice memory. To comprehensively investigate MLLM's performance on the association, we formulate the association task and devise a standard benchmark based on adjective and verb semantic concepts. Instead of costly data annotation and curation, we propose a convenient annotation-free construction method transforming the general dataset for our association tasks. Simultaneously, we devise a rigorous data refinement process to eliminate confusion in the raw dataset. Building on this database, we establish three levels of association tasks: single-step, synchronous, and asynchronous associations. Moreover, we conduct a comprehensive investigation into the MLLMs' zero-shot association capabilities, addressing multiple dimensions, including three distinct memory strategies, both open-source and closed-source MLLMs, cutting-edge Mixture-of-Experts (MoE) models, and the involvement of human experts. Our systematic investigation shows that current open-source MLLMs consistently exhibit poor capability in our association tasks, even the currently state-of-the-art GPT-4V(vision) also has a significant gap compared to humans. We believe our benchmark would pave the way for future MLLM studies.
Demo
Results

Publications
If you find our paper, data or code usefull, please cite:
@article{li2024labyrinth,
title={The Labyrinth of Links: Navigating the Associative Maze of Multi-modal LLMs},
author={Li, Hong and Li, Nanxi and Chen, Yuanjie and Zhu, Jianbin and Guo, Qinlu and Lu, Cewu and Li, Yong-Lu},
journal={arXiv preprint arXiv:2410.01417},
year={2024}
}
Disclaimer

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
