Abstract
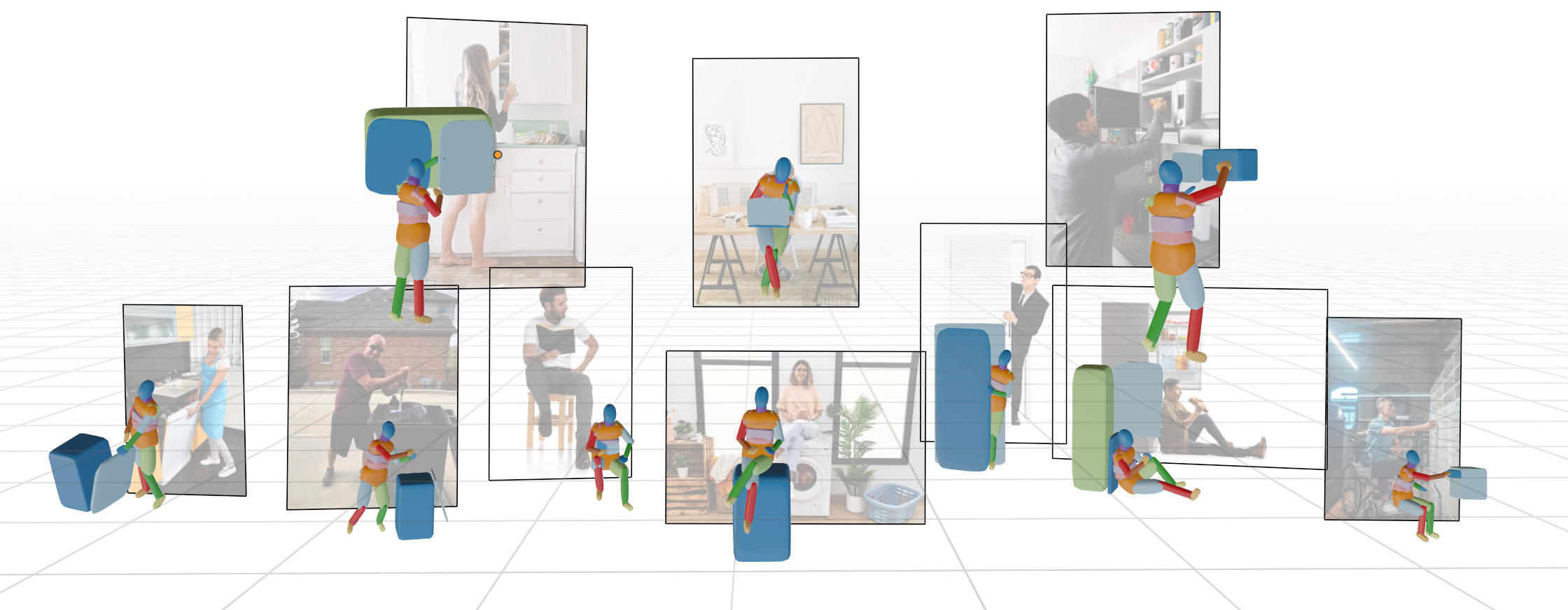
Embedding Human and Articulated Object Interaction (HAOI) in 3D is an important direction for a deeper human activity understanding. Different from previous works that use parametric and CAD models to represent humans and objects, in this work, we propose a novel 3D geometric primitive-based language to encode both humans and objects. Given our new paradigm, humans and objects are all compositions of primitives instead of heterogeneous entities. Thus, mutual information learning may be achieved between the limited 3D data of humans and different object categories. Moreover, considering the simplicity of the expression and the richness of the information it contains, we choose the superquadric as the primitive representation. To explore an effective embedding of HAOI for the machine, we build a new benchmark on 3D HAOI consisting of primitives together with their images and propose a task requiring machines to recover 3D HAOI using primitives from images. Moreover, we propose a baseline of single-view 3D reconstruction on HAOI. We believe this primitive-based 3D HAOI representation would pave the way for 3D HAOI studies.
Method
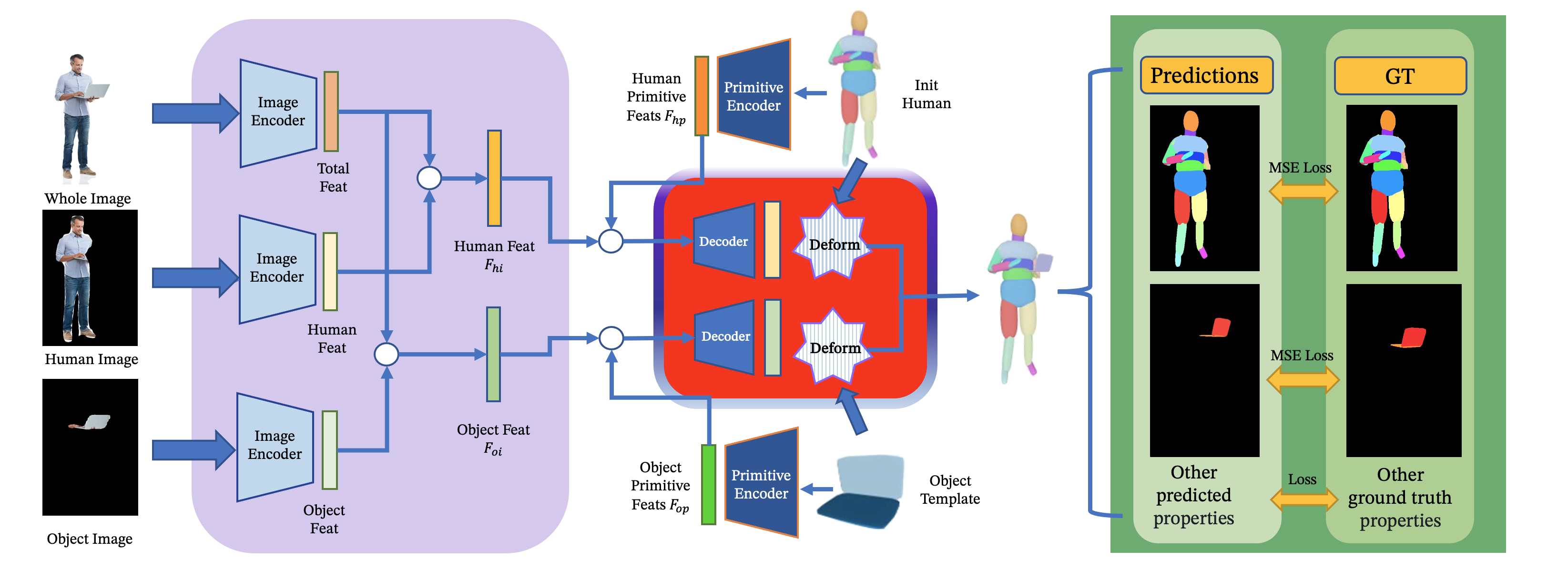
In the purple block are the image encoders. Superquadric-composed shapes are also encoded to predict primitive features. Then the image features and primitive features are contacted together to predict the 6-Dof of each input superquadric part. Deformation is based on these predictions. The deformed shapes are then rendered back to 2D and some losses are computed based on some supervisions.
Dataset Annotation
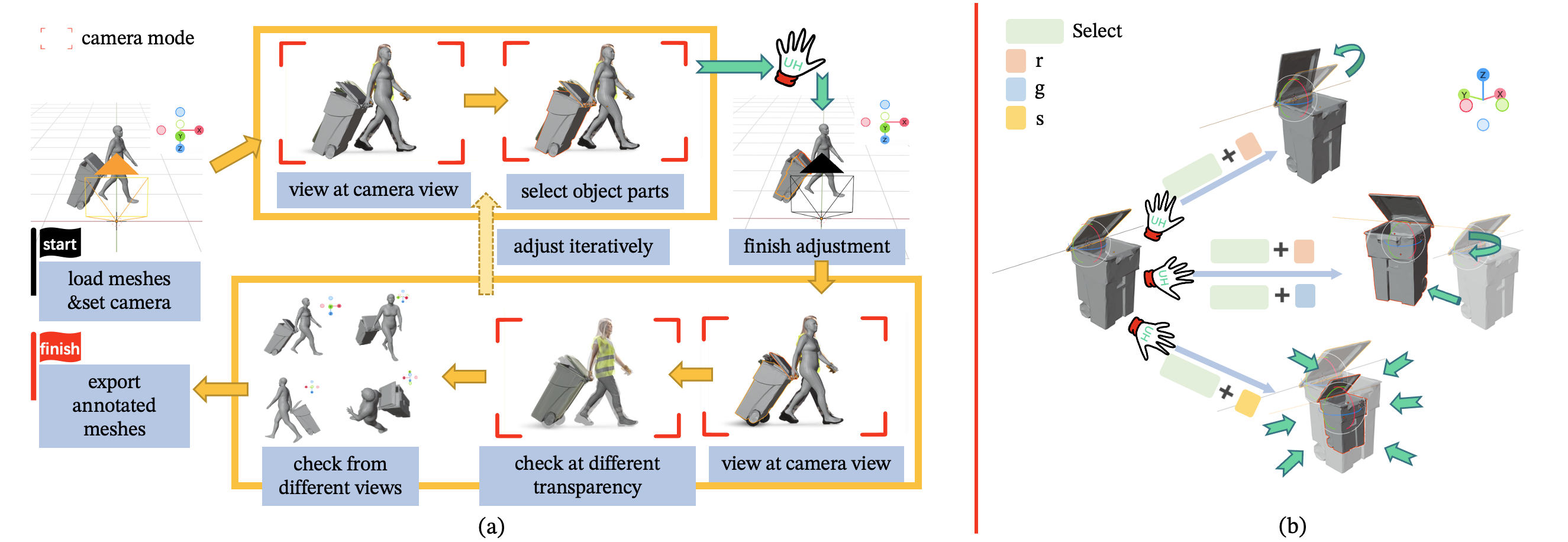
For each category, we select CAD models with the closest appearance to the object in the image. Textures are not taken into consideration when choosing CAD models. For each image instance, the fine-tuned SMPL mesh and the object CAD template model are imported into Blender. Then we set the camera parameters predicted by ROMP and the original image as the background image in the camera view mode. During the annotation process, we did not deform the human. All operations take place on the object. Using the UH, we first adjust the object template to the object state shown in the image. Then we switch between the camera view mode and the whole world view mode to check (1) if the annotated object projection aligns perfectly with the background image, and (2) if the spatial arrangement with the human is reasonable based on the information in the image, and (3) if it is consistent with common sense, while continue adjusting the object using the UH. The annotation for one image is finished until the object satisfies the three conditions above. When the annotation is finished, we export the object parts.